o 목표
- 데이터 분석의 의미와 다양한 방법
- 데이터 분석시 각 알고리즘의 아이디어
- 신경망 알고리즘과 비신경망 알고리즘 학습 및 비교
- 신경망 알고리즘의 진화 과정에서 발생한 특징과 한계점 그리고 개선 포인트
- Tool base가 아닌 알고리즘으로 핵심 파악
- 수식으로 설명된 알고리즘들을 구체적으로 이해
- 파이썬으로 신경망 모델 제작 및 실험시 고려사항
o 역사
- 컴퓨터가 나오기 이전부터 인공지능 개념 연구
- 컴퓨터 발명 후 구체적인 연구 및 결과 발표
- 신경망 알고리즘도 많은 연구가 있었으나 세대별로 암흑기가 있음
- 명확한 한계가 있음
o 신경망
- 인간 두뇌 복제 방식으로 인공지능 접근
- 80~90년도에 인공신경망의 등장으로 한동안 인기
- 인공신경망의 약점이 나오고 한계점 극복이 어려워 한동안 침체기
- 06년 제프리 힌튼 교수가 심층 신뢰 신경망(DBN) 발표
- 현재 딥러닝 알고리즘이 주류
o 순서
- 각 알고리즘의 특징 및 한계 이해가 필요하고 Linear Classifier -> Perceptron -> Artificial Neural Network -> Deep Learning 순으로 학습 하는 것이 좋음
- 딥러닝이 신경망 네트워크에서 최신의 알고리즘으로 생각하면 됨
o AI vs Machine Learning vs Deep Learning
- AI가 가장 큰 개념이고 AI 중에 하나가 머신러닝 그리고 머신러닝 방법 중 하나가 딥러닝 AI수준에선느 데이터마이닝, Pattern Recognition 등이 더 포함되어 있음
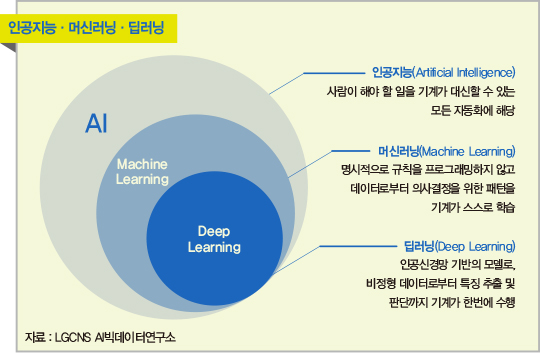
o Machine Learning
- Tom Michell : 작업(T)에 대해 성능 지표(P)로 측정된 데이터가 경험(E)에 따라 향상되었다면, 그 컴퓨터 프로그램은 작업(T)와 성능 지표(P)에 대해 경험(E)으로부터 학습했다고 말할 수 있다.
- Arthur Samuel : 컴퓨터에게 명시적으로 프로그래밍 하지 않고 학습을 할 수 있는 능력을 주는 연구 분야
- Learing : ML알고리즘이 특정 차원에 따라 최적화를 시도하고, 오류를 최소화하거나 예측이 사실일 가능성을 극대화
- 대부분 머신러닝의 알고리즘은 오류를 최소화하는 과정을 학습이라고 한다. 오차가 줄어들면 줄어들수록 성능이 좋아지는 것이며, 점진적으로 답을 찾아가는 것이다
- 오차를 줄이는 과정은 수학적 모델로 설명이 되어야한다. 이것을 오차 함수(Error function), 손실 함수(loss function), 목적함수(objective function)이라고 한다.
** 대학교에서 인공지능 연구실, 데이터 마이닝 연구실, 최적화 연구실 이름을 가진곳은 대부분 AI를 전공하고 있을 확률이 높음
o 그래서 AI와 머신러닝, 딥러닝으로 무엇을 알고싶은 것일까?
- 회사가 미래를 예측할 수 있기 위해 AI를 활용한다. 미래를 예측할 수 있으면 할 수 있는 것이 매우 많다. 고로 예측 모델이 가장 큰 포지션을 차지한다.
o Predictive Model의 접근방법
- 경험적인 접근 : 우리는 과거에 무엇을 기반으로 예측했는가?
- 공학적인 접근 : 객관적인 근거를 기반으로 예측
- 과거에 수집된 데이터를 기반으로 미래를 예측할 수 있고, 이때 목표(Target Value)를 정확히 설정해야한다.
- 전세자금대출할때 10 ~ 15년을 보고 상환이 진행되는데, 은행에서는 지금 당장 돈이 나간다. 미래에 이 사람이 착실히 상환할 수 있는 사람인지 예측이 필요하다.
- 그래서 데이터 분석에서 제일 처음으로 할 것은 이 데이터를 분석하여 어떤 정보를 알고 싶은지 도출해야함(타겟 벨류)
| Attribute or Feature Vector | Target Value class |
||||
| 이름 | 나이 | 직장 | 잔고 | 상환여부 | |
| instance | 김씨 | 20 | 대기업 | 500만원 | O |
| 박씨 | 54 | 중견기업 | 1억 | X | |
| 최씨 | 33 | 개인사업자 | 20억 | O | |
o 데이터 분석의 접근방법
- Target Value의 존재 유무에 따라 데이터 분석의 접근법이 달라진다.
- Supervised Learning : 우리가 알고 있는 대다수의 알고리즘이며, 신경망 알고리즘도 해당 알고리즘이다. 오차를 줄이는게 머신러닝이고, 오차가 난다는 것은 답이 있어야한다. 정답이 있어야 오차를 구할 수 있음. 오차가 나온다는 것이 Supervised Learning이다.
- unsuperised learning : 입력값에 대한 타겟벨류가 없다. (비지도학습)
o 데이터 분석하여 우리가 알아야 내야할 것은? (예측모델 중 분류모델)
- 만들어진 모델은 현업에서 어떻게 적용할 것인가? 비즈니스 분야로 한정하면 예측모델 중 분류(Classification)모델을 가장 선호한다.
- 분류 모델을 생성하면 분류된 결과 뿐만아니라 꼭 개별 인스턴스의 계층확률 추정이 필요하다.
- 현업에 갔을때 단순이 분류만 했을때 그것을 사용할 수 없다. 예를들어 분류모델을 써서 통신사 약정이 만기되고 다른 통신사로 갈아탈 사람을 분류했다고 치자. 그 사람들 전부에게 갈아타지 말고 우리 통신사 계속 써라라고 마케팅하면 좋겠으나, 현실적으로 비용 문제가 있기때문에 그 와중에서 갈아탈 확률이 낮은 사람으로 정렬할 필요가 있다.
- 확률로 표현하기 힘든 경우가 있는데 이때는 스코어링이라고 다른 방법으로 표시할수 있다.
- 예측의 분류모델을 만들때는 왜 이 모델에 이 수식이 이용한 이유가 있어야 한다.
o 예측 모델을 어떻게 만들 것인가?
- 다양한 방법이 존재하는데, 데이터를 읽어가면서 모델을 생성하거나 모델을 먼저 결정하고 데이터에 맞추는 경우가 있다.
o 그러고 보니 빅데이터와 통계의 차이는?
- 빅데이터 : Classification, Prediction
- 통계 : Regression, Prediction
- 빅데이터와 통계의 공통점은 둘다 예측이 포함되어있다.
- 통계학에서는 모집단에서 분석한 결과를 모수라고 하고 파라미터라고 한다. 평균, 분산, 표준분산을 대표적으로 모수라고한다. 현실세계에서는 전체 모집단을 분석할 수가 없기때문에 샘플링 한다. 샘플링한 데이터를 기반으로 분석한 결과가 있을 것이고, 그것을 통계량이라고 한다. 통계량이 Statistics이다.
- 하여 통계의 정의는 샘플데이터를 기반으로 분석(통계량)하여 모집단을 추정하는 것을 통계라고 한다.
- 모수적 접근이라는 말도 통계학적으로 접근하겠다는 말이다. 특정 공식을 쓰기 위해 조건을 맞추는 것이다.
(하나의 공식에서도 일부 조건이 안 맞을 경우 맞추기 위한 방법이 나열되어 있어 통계학 책이 두껍다)
- 비모수적 접근은 데이터를 분석할때 데이터만 분석하는거지 전제조건이 없다.

o 그래서 어떤 절차로 배워야할까?
- 비신경망 모델 -> 선형 모델 -> 신경망 모델 순으로 배울 것
- 비신경망 모델 : 예측모델 접근방법, Decision Tree 모델을 이용한 예측모델
- 선형모델 : 선형모델 개념, 선형회귀분석&로지스틱 회귀분석, 딥러닝시 필요한 수학개념(선형회귀분석과 선형분류모델구분을 잘해야함)
- 신경망모델 : Perception, Artificial Neural network, DeepLearning
=> 신경망 모델과 다른 모델의 차이점을 비교하고, 신경망 모델이 왜 나왔는지, 신경망 모델의 장단점도 파악하고 성능개선 방법을 배워야한다.
o 추가 내용
- 알고리즘을 보통 모델이라고 하고 모델은 목적 달성을 위해 현실세계를 단순하게 표현하고 단순할수록 좋음
- 가우스 등 수학적으로 검증된 이론으로 모델을 검증해야 객관성이 담보가 된다.
- 전문가가 전문가에게 설명할때는 그래프로 하고 비전문가에게 설명할때는 시각화하여 보여줘야 한다.
'Develop > AI' 카테고리의 다른 글
| 인공지능(신경망, 딥러닝) 교육 정리(Logistic Regression) (0) | 2023.01.01 |
|---|---|
| 인공지능(신경망, 딥러닝) 교육 정리 (Linear Regression) (0) | 2022.12.28 |
| 인공지능(신경망, 딥러닝) 교육 정리 [Linear Classifier] (0) | 2022.12.28 |
| 인공지능(신경망, 딥러닝) 교육 정리 [Decision Tree] (0) | 2022.12.28 |
| 인공지능(신경망, 딥러닝) 교육 정리 [Entropy, Information Gain] (0) | 2022.12.27 |








최근댓글